The 3 Reasons Why I Have Permanently Switched From Pandas To Polars
I came for the speed, but I stayed for the syntax.
At the time of writing this post, it’s been six years since I landed my first job in data science. And, for those entire six years spent doing data science, Pandas has been the foundation of all my work: exploratory data analyses, impact analyses, data validations, model experimentation, you name it. My career was built on top of Pandas!
Needless to say, I had some serious Pandas lock-in.
That is, until I discovered Polars, the new “blazingly fast DataFrame library” for Python.
In this article, I’ll explain:
- What
Polarsis, and what makes it so fast; - The 3 reasons why I have permanently switched from
PandastoPolars:- The
.listnamespace; .scan_parquet()and.sink_parquet();- Data-oriented programming.
- The

Introducing Polars: The Fastest Python Dataframe Library That You’ve (Maybe) Never Heard Of.
Maybe you’ve heard of Polars, maybe you haven’t! Either way it’s slowly taking over Python’s data-processing landscape:
- Leonie Monigatti recently wrote a comprehensive timing comparison of
PandastoPolars. - Wei-Meng Lee already published a Getting Started guide last summer.
- Carl M. Kadie wrote a few months ago on one of the biggest surface-level differences between
PandasandPolars–Polars's lack of an index.
So what makes Polars so fast? From the Polars User Guide:
Polarsis completely written inRust(no runtime overhead!) and usesArrow– the native arrow2Rustimplementation – as its foundation…Polarsis written in Rust which gives it C/C++ performance and allows it to fully control performance critical parts in a query engine…
…Unlike tools such as dask – which tries to parallelize existing single-threaded libraries like NumPy and Pandas – Polars is written from the ground up, designed for parallelization of queries on DataFrames…
And there you have it. Polars is not just a framework for alleviating the single-threaded nature of Pandas, like dask or modin; rather, it is a full makeover of the Python dataframe, including the highly optimal Apache Arrow columnar memory format as its foundation, and its own query optimization engine to boot. And the results on speed are mind-blowing (as per h2oai’s data benchmark):
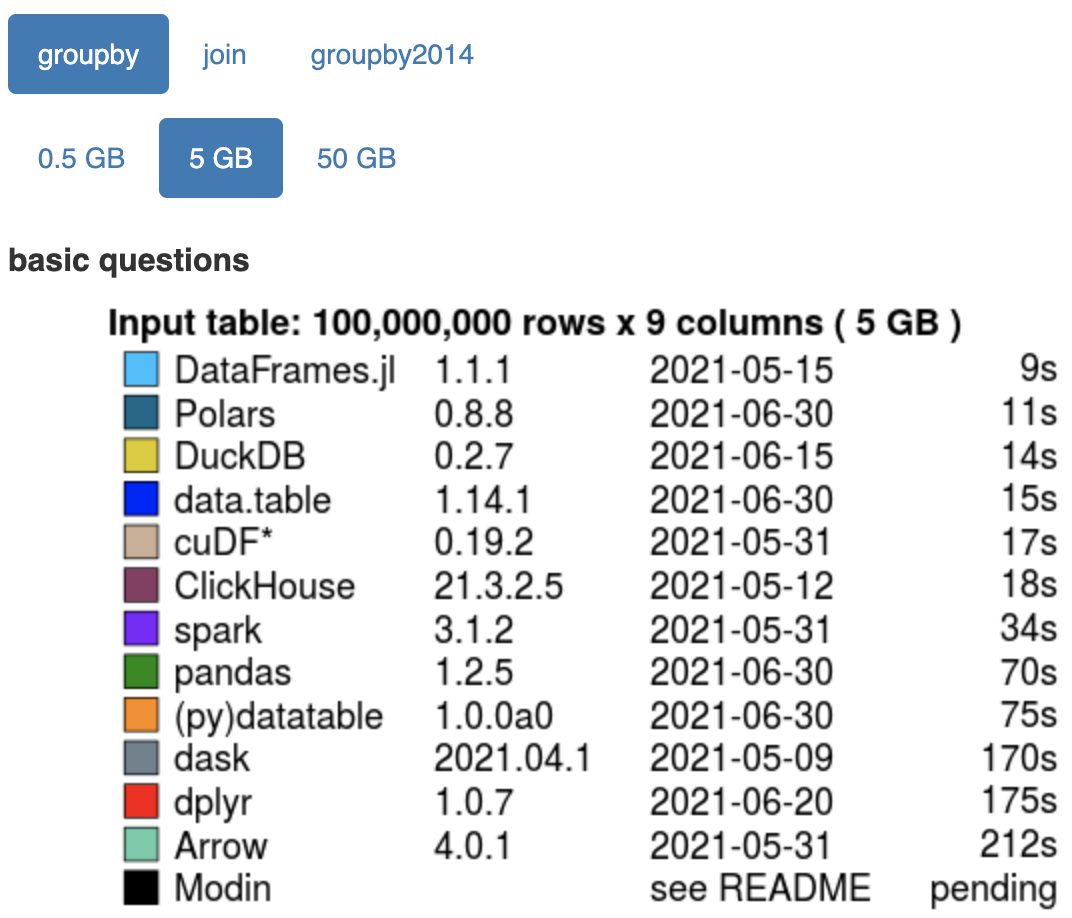
On a groupby operation of a 5GB dataframe, Polars is more than 6 times faster than Pandas!
This speed alone is enough to get anyone interested. But as you’ll see in the rest of this article, the speed is what got me interested, but it’s really the syntax that made me fall in love.
The 3 Reasons Why I Have Permanently Switched from Pandas to Polars
1. The .list Namespace
Imagine the following scenario in Pandas: you have a dataset of families and some information about them, including a list of all the members of the family…
import pandas as pd
df = pd.DataFrame({
"last_name": ["Johnson", "Jackson", "Smithson"],
"members": [["John", "Ron", "Con"], ["Jack", "Rack"], ["Smith", "Pith", "With", "Lith"]],
"city_of_residence": ["Boston", "New York City", "Dallas"]
})
print(df)
>>>> last_name members city_of_residence
0 Johnson [John, Ron, Con] Boston
1 Jackson [Jack, Rack] New York City
2 Smithson [Smith, Pith, With, Lith] Dallas
For your analysis, you want to create a new column from the first element of the members list. How do you do this? A search of the Pandas API will leave you lost, but a brief stackoverflow search will show you the answer!
The prevailing method to extract an element of a list in a Pandas column is to use the .str namespace (stackoverflow ref1, stackoverflow ref2), like this:
df["family_leader"] = df["members"].str[0]
print(df)
>>>> last_name members city_of_residence family_leader
0 Johnson [John, Ron, Con] Boston John
1 Jackson [Jack, Rack] New York City Jack
2 Smithson [Smith, Pith, With, Lith] Dallas Smith
If you’re like me, you’re probably wondering, “why do I have to use the .str namespace to handle a list data-type?”.

Unfortunately, Pandas's .str namespace can’t do all list operations that one might desire. In Polars, however, this is not a problem. By conforming to Apache Arrow’s columnar data format, Polars has all standard data-types, and appropriate namespaces for handling all of them – including lists:
import polars as pl
df = pl.DataFrame({
"last_name": ["Johnson", "Jackson", "Smithson"],
"members": [["John", "Ron", "Con"], ["Jack", "Rack"], ["Smith", "Pith", "With", "Lith"]],
"city_of_residence": ["Boston", "New York City", "Dallas"]
})
df = df.with_columns([
pl.col("members").list.get(0).alias("family_leader")])
print(df)
>>>> ┌───────────┬─────────────────────────────┬───────────────────┬───────────────┐
│ last_name ┆ members ┆ city_of_residence ┆ family_leader │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ list[str] ┆ str ┆ str │
╞═══════════╪═════════════════════════════╪═══════════════════╪═══════════════╡
│ Johnson ┆ ["John", "Ron", "Con"] ┆ Boston ┆ John │
│ Jackson ┆ ["Jack", "Rack"] ┆ New York City ┆ Jack │
│ Smithson ┆ ["Smith", "Pith", … "Lith"] ┆ Dallas ┆ Smith │
└───────────┴─────────────────────────────┴───────────────────┴───────────────┘
That’s right: Polars is so explicit about data-types, that it even tells you the data-type of each column in your dataframe every time you print it!
It doesn’t stop here though. Not only does the Pandas API require use of one data-type’s namespace for handling of another data-type, but the API has become so bloated that there are often many ways to do the same thing. This can be confusing, especially for newcomers. Consider the following code snippet:
import pandas as pd
df = pd.DataFrame({
"a": [1, 1, 1],
"b": [4, 5, 6]
})
column_name_indexer = ["a"]
boolean_mask_indexer = df["b"]==5
slice_indexer = slice(1, 3)
for o in [column_name_indexer, boolean_mask_indexer, slice_indexer]:
print(df[o])
In this code snippet, the same Pandas syntax df[...] can do three distinct operations: retrieving a column of the dataframe, performing a row-based boolean mask on the dataframe, and retrieving a slice of the dataframe by index.
Another troubling example is that, to process dict columns with Pandas, you usually have to do a costly apply() function; Polars, on the other hand, has a struct data-type for handling dict columns directly!
In Pandas, you can’t do everything you want, and for the things that you can do, there’s sometimes multiple ways to do them. Compare this with Polars, where you can do everything, the data-types are clear, and there’s usually only one way to do the same thing.
2. .scan_parquet() and .sink_parquet()
One of the best things about Polars is the fact that it offers two API’s: an eager API and a lazy API.
The eager API runs all commands in-memory, like Pandas.
The lazy API, however, does everything only when explicitly asked for a response (e.g. with a .collect() statement), a bit like dask. And, upon being asked for a response, Polars will lean on its query optimization engine to get you your result in the fastest time possible.
Consider the following code snippet, comparing the syntax of the Polars eager DataFrame to that of its lazy counterpart LazyFrame:
import polars as pl
eager_df = pl.DataFrame({
"a": [1, 2, 3],
"b": [4, 5, 6]
})
lazy_df = pl.LazyFrame({
"a": [1, 2, 3],
"b": [4, 5, 6]
})
The syntax is remarkably similar! In fact, the only major difference between the eager API and the lazy API is in dataframe creation, reading, and writing, making it quite easy to switch between the two:
| Eager API | Lazy API | |
|---|---|---|
| Dataframe Creation | DataFrame() | LazyFrame() |
| Input CSV | read_csv() | scan_csv() |
| Input Parquet | read_parquet() | scan_parquet() |
| Output Parquet | write_parquet() | sink_parquet() |
| … | … | … |
And that brings us to .scan_parquet() and .sink_parquet().
By using .scan_parquet() as your data input function, LazyFrame as your dataframe, and .sink_parquet() as your data output function, you can process larger than memory datasets! Now that’s cool, especially when you compare it with what the creator of Pandas himself, Wes McKinney, has said about Pandas's memory footprint:

3. Data-Oriented Programming
Pandas treats dataframes like objects, enabling Object-Oriented Programming; but Polars treats dataframes as data tables, enabling Data-Oriented Programming.
Let me explain.
With dataframes, most of what we want to do is run queries or transformations; we want to add columns, pivot along two variables, aggregate, group by, you name it. Even when we want to subset a dataset into train and test for training and evaluating a machine learning model, those are SQL-like query expressions in nature.
And it’s true – with Pandas, you can do most of the transformations, manipulations, and queries on your data that you would want. However, frustratingly, some transformations and queries simply cannot be done in one expression, or one query if you will. Unlike other query and data-processing languages like SQL or Spark, many queries in Pandas require multiple successive, distinct assignment operations, and this can make things messy. Consider the following code snippet, where we have a dataframe of people and their ages, and we want to see how many people there are in each decade:
import pandas as pd
df = (
pd.DataFrame({
"name": ["George", "Polly", "Golly", "Dolly"],
"age": [3, 4, 13, 44]
})
)
df["decade"] = (df["age"] / 10).astype(int) * 10
decade_counts = (
df
.groupby("decade")
["name"]
.agg("count")
)
print(decade_counts)
>>>> decade
0 2
10 1
40 1
There’s no way around it – we have to do our query in three assignment operations. To get it down to two operations, we could have used the rarely seen .assign() operator in place of the df["decade"] = ... operation, but that’s it! It might not seem like a big problem here, but when you find yourself needing seven, eight, nine successive assignment operations to get the job done, things can start to get a bit unreadable and hard to maintain.
In Polars, though, this query can be cleanly written as one expression:
import polars as pl
decade_counts = (
pl.DataFrame({
"name": ["George", "Polly", "Golly", "Dolly"],
"age": [3, 4, 13, 44]
})
.with_columns([
((pl.col("age") / 10).cast(pl.Int32) * 10).alias("decade")
])
.groupby("decade")
.agg(
pl.col("name").count().alias("count")
)
)
print(decade_counts)
>>>> ┌────────┬───────┐
│ decade ┆ count │
│ --- ┆ --- │
│ i32 ┆ u32 │
╞════════╪═══════╡
│ 0 ┆ 2 │
│ 10 ┆ 1 │
│ 40 ┆ 1 │
└────────┴───────┘
So smooth.
You might read that and think to yourself “why do I want to do everything in one expression though?”. It’s true, maybe you don’t. After all, many data pipelines use intermediate queries, save intermediate results to tables, and query those intermediate tables to get to the final result, or even to monitor data quality.
But, like SQL, Spark, or other non-Pandas data-processing languages, Polars gives you 100% flexibility to break up your query where you want to in order to maximize readability, while Pandas forces you to break up your query according to its API’s limitations. This is a huge boon not only for code-readability, but also for ease of development!
Further still, as an added bonus, if you use the lazy API with Polars, then you can break your query wherever you want, into as many parts as you want, and the whole thing will be optimized into one query under the hood anyway.
Conclusion

What I’ve discussed in this article is just a glimpse into the superiority of Polars over Pandas; there remain still many functions in Polars that harken to SQL, Spark, and other data-processing languages (e.g. pipe(), when(), and filter(), to name a few).
And while Polars is now my go-to library for data processing and analysis in Python, I do still use Pandas for narrow use-cases like styling dataframes for display in reports and presentations or communication with spreadsheets. That said, I fully expect Polars to subsume Pandas bit by bit as time goes on.
What Next?
Getting started with a new tool is hard; especially if it’s a new dataframe library, something which is so pivotal to our work as data scientists! I got started by taking Liam Brannigan’s Udemy course “Data Analysis with Polars”, and I can highly recommend it – it covers all the basics of Polars, and helped make the transition quite easy for me (I receive no referral bonus from suggesting this course; I simply liked it that much!). And that brings me to my final point…
Acknowlegments
A special thank you to Liam Brannigan for your Polars course, without which I’m not sure I would have made the transition from Pandas to Polars. And, of course, a huge thank you to Ritchie Vink, the creator of Polars! Not only have you created an awesome library, but you promptly responded to my questions and comments about Polars on both LinkedIn and Github – you’ve not only created an amazing tool, but also a beautiful community around it. And to you, the reader – thank you for reading; I wish you happy data-crunching :)
Liked what you read? Feel free to reach out on , , , , and .